
목표
자바의 멀티쓰레드 프로그래밍에 대해 학습하세요.
학습할 것 (필수)
- Thread 클래스와 Runnable 인터페이스
- 쓰레드의 상태
- 쓰레드의 우선순위
- Main 쓰레드
- 동기화
- 데드락
쓰레드
쓰레드는 실행 중인 프로그램 내에서 '또 다른 실행의 흐름을 형성하는 주체'를 의미한다.
예를 들어서 다음과 같이 프로그램을 실행하면 가상머신은 하나의 쓰레드를 생성해서 main 메소드의 실행을 담당하게 한다.
public class CurrentThreadName {
public static void main(String[] args) {
Thread ct = Thread.currentThread();
String name = ct.getName(); // 쓰레드의 이름 변환
System.out.println(name);
}
}
// 출력 : main
main 메소드를 실행을 담당하는 쓰레드의 정보를 다음과 같이 참조를 얻을 수 있다.
Thread ct = Thread.currentThread();
쓰레드 생성
쓰레드를 생성하면 생성한 만큼 프로그램 내에서 다른 실행의 흐름이 만들어진다.
public class MakeThreadDemo {
public static void main(String[] args) {
Runnable task = () -> { // 쓰레드가 실행할 내용
int n1 = 10;
int n2 = 20;
final String name = Thread.currentThread().getName();
System.out.println(name + ": " + (n1 + n2));
};
Thread t = new Thread(task);
t.start(); // 쓰레드 실행
System.out.println("End " + Thread.currentThread().getName());
}
}
// 출력
// End main
// Thread-0: 30
쓰레드 생성을 위해 가장 먼저 할 일은 Runnable 인터페이스를 구현하는 클래스의 인스턴스를 생성하는 일이다. 그런데 Runnable은 다음 추상 메소드 하나만 존재하는 함수형 인터페이스이다.
void run()따라서 람다식을 기반으로 메소드의 구현과 인스턴스의 생성을 동시에 진행할 수 있다. 이렇게 구현된 메소드는 새로 만든 쓰레드의 생성자 인자로 전달하여 새로 생긴 쓰레드가 실행한다.
또 다른 생성자 인자로 쓰레드의 이름을 넘겨줄 수도 있다.
Thread t = new Thread(task, "thread name");
또한 실행 결과에서는 main 쓰레드가 먼저 일을 마친 상황을 알 수있다. 쓰레드의 생성에는 시간이 걸리므로 이러한 상황은 쉽게 연출될 수 있다. 그러나 main 쓰레드가 일을 마쳤다고 해서 프로그램이 종료되지 않는다. 모든 쓰레드가 일을 마치고 소멸되어야 프로그램이 종료된다. 따라서 위 예제에서 생성된 쓰레드는 자신의 일을 마칠 충부한 시간을 갖는다. 참고로 위와 같이 생성된 쓰레드는 자신의 일을 마치면 자동으로 소명된다. (여기서 말하는 쓰레드의 소멸은 쓰레드의 생성을 위해 할당했던 모든 자원의 해제를 의미한다.)
"쓰레드는 자신의 일을 마치면(run 메소드의 실행을 완료하면) 자동으로 소멸된다."
public class ThreadMultiDemo {
public static void main(String[] args) {
Runnable task1 = () -> { //20 미만 짝수 출력
for (int i = 0; i < 20; i++) {
if (i % 2 == 0) {
System.out.print(i + " ");
}
}
};
Runnable task2 = () -> { //20 미만 짝수 출력
for (int i = 0; i < 20; i++) {
if (i % 2 == 1) {
System.out.print(i + " ");
}
}
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
}
}
// 출력
// 1 3 5 7 0 2 4 9 6 8 11 10 13 12 15 14 17 16 19 18
// 1 3 5 7 9 11 13 15 17 19 0 2 4 6 8 10 12 14 16 18
매번 실행 할 때마다 결과가 다르다. 쓰레드는 각각의 독립적인 실행을 한다.보통 CPU의 코어 하나가 할당되어 동시에 실행을 이뤄나간다.
만약 쓰레드가 코어의 수보다 많이 생성된다면,
CPU의 코어가 하나이던 시절의 멀티 쓰레드 프로그래밍에는 다음과 같은 장점이 있었다.
- CPU의 코어가 둘 이상인 것과 같은 효과를 보였다.
- 하나의 코어가 둘 이상의 쓰레드를 담당하므로 코어의 활용도가 높았다.
코어가 하나이고 쓰레드가 둘 이상이면 이들은 코어를 나누어 차지하며 실행을 이어 나간다. 그런데 그 나누는 시간의 조각이 매우 작기 때문에 동시에 실행되는 효과를 충분히 누릴 수 있었다. (그만큼 코어가 쉬는 시간을 최소화할 수 있어서 코어의 활용도도 높았다.) 마찬가지로 멀티 코어 CPU 기반에서도 코어의 수보다 많은 수의 쓰레드가 생성되면 쓰레드들은 코어를 나누어 차지하게 된다. 물론 나누는 시간의 조각이 매우 작기 때문에 프로그램 사용자는 이러한 사실을 눈치채지 못한다.
쓰레드의 상태
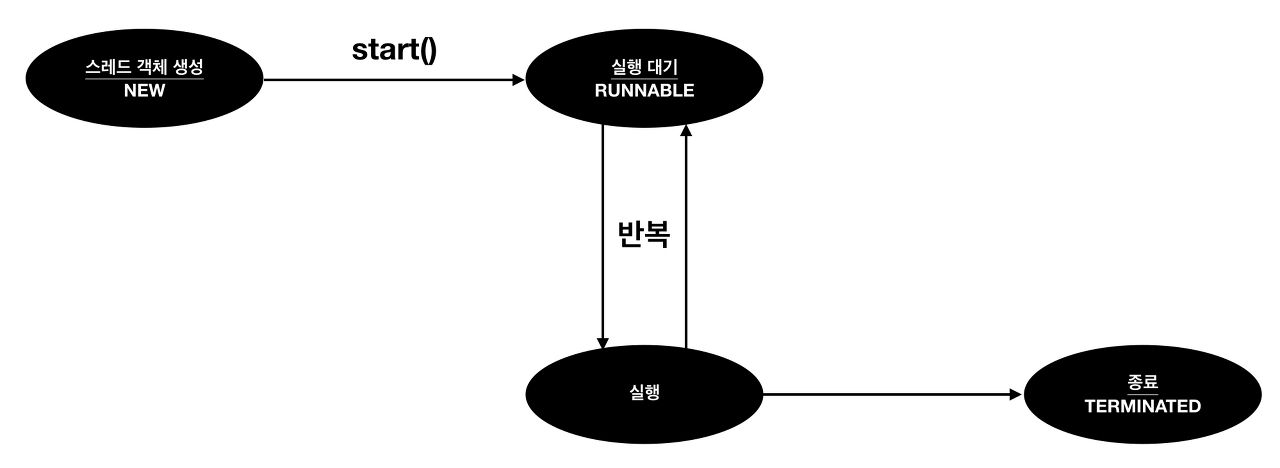
쓰레드의 우선순위
/**
* The minimum priority that a thread can have.
*/
public static final int MIN_PRIORITY = 1;
/**
* The default priority that is assigned to a thread.
*/
public static final int NORM_PRIORITY = 5;
/**
* The maximum priority that a thread can have.
*/
public static final int MAX_PRIORITY = 10;
우선순위의 범위는 1 ~ 10 까지 있을수 있다. 그리고 쓰레드를 생성하고 난 뒤에는 다음과 같이 우선순위를 정할 수 있다.
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.setPriority(Thread.MIN_PRIORITY);
t1.setPriority(Thread.MAX_PRIORITY);
동기화
만약의 둘 이상의 쓰레드가 하나의 메모리 공간에(변수에) 접근했을 때 동기화 문제가 발생한다.
public class MultiAccess {
public static Counter cnt = new Counter();
public static void main(String[] args) throws InterruptedException {
Runnable task1 = () -> {
for (int i = 0; i < 1000; i++) {
cnt.increment();
}
};
Runnable task2 = () -> {
for (int i = 0; i < 1000; i++) {
cnt.decrement();
}
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
t1.join(); // t1이 참조하는 쓰레드의 종료를 기다림
t2.join(); // t2가 참조하는 쓰레드의 종료를 기다림
System.out.println(cnt.getCount());
}
}
class Counter {
private int count = 0; // 두 쓰레드에 의해 공유되는 변수
public void increment() {
count++;
}
public void decrement() {
count--;
}
public int getCount() {
return count;
}
}
// 출력
// -80
// 12
하나는 1000번 더하고 하는 1000번 뺐으면 0 이 나와야 하는데 -80 이 나오고 12가 출력됬다. 따라서
"둘 이상의 쓰레드가 동일 한 변수에 접근하는 것은 문제를 일으킬 수 있다."
따라서 위 예제와 같은 상황에서는 둘 이상의 쓰레드가 동일한 메모리 공간에 접근해도 문제가 발생하지 않도록 '동기화' 라는 것을 해야한다.
또 다른 예시로 통장 잔고에 1000원이 있는데, A가 800원 빼가고 B가 1000원 빼가는데, A가 빼낸 다음 잔고가 200원이 되고 B 가 빼갈 때 잔고부족으로 떠야 하지만 동시에 접근을 하게 되면 A가 접근할때도 잔고 1000원 B가 접근할 때도 잔고 1000원인 꼴이 되어 B가 1000원을 빼갈 수 있다.
따라서 동시에 접근하지 말고 한 쓰레드만 접근하도록 하게 해주면된다. (동기화)
동기화 메소드
synchronized public void increment() {
count++;
}synchronized 를 선언하면 동기화가 이루어진다. 따라서 이 메소드는 한순간에 한 쓰레드의 접근만을 허용하게 된다. 예를 들어서 이 메소드를 두 쓰레드가 동시에 호출하면, 조금이라도 빨리 호출한 쓰레드가 메소드를 실행하게 되고, 다른 한 쓰레드는 대기하고 있다가 먼저 호출한 쓰레드가 실행을 마쳐야 비로소 실행하게 된다.
동기화 메서드로 만들고 출력을 확인해보자.
class Counter {
private int count = 0; // 두 쓰레드에 의해 공유되는 변수
synchronized public void increment() {
count++;
}
synchronized public void decrement() {
count--;
}
public int getCount() {
return count;
}
}
// 출력 : 0동기화가 잘 된것을 볼수 있다.
만약 count 가 증가되면서 로그를 찍는 코드로 수정이 되었다고 해보자.
synchronized public void increment() {
synchronized (this) {
count++;
}
System.out.println("1 증가되어 " + count + " 가 되었습니다.");
}그렇다면 콘솔에 출력하는 부분은 동기화가 필요없다 따라서 부분만 동기화 처리를 다음과 같이 해줄 수 있다.
그러면 이제 메소드 자체에 동기화를 풀어줘도 되니 최종적으로 다음과 같은 모습이다.
public void increment() {
synchronized (this) {
count++;
}
System.out.println("1 증가되어 " + count + " 가 되었습니다.");
}
데드락
하나에 쓰레드만 접근가능한 동기화에서 만약 접근한 쓰레드가 계속 접근하고 있다면 ? 기다리고 있는 쓰레드들은 하염없이 기다리게 되는데 이것을 데드락이라고 한다.
그렇가면 데드락은 어떻게 해결하는가?
- timeout (기다리는데 시간제한을 두거나)
- Atomic 타입의 변수를 사용하는 것이다.
Atomic
Atomic 클래스는 CAS(compare-and-swap)를 이용하여 동시성을 보장한다. 여러 쓰레드에서 데이터를 접근해도 문제가 없습니다. 심지어 synchronized 보다 비용이 훨씬 적다.
public class AtomicDemo {
public static AtomicCounter cnt = new AtomicCounter();
public static void main(String[] args) throws InterruptedException {
Runnable task1 = () -> {
for (int i = 0; i < 1000; i++) {
cnt.increment();
}
};
Runnable task2 = () -> {
for (int i = 0; i < 1000; i++) {
cnt.decrement();
}
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
t1.join(); // t1이 참조하는 쓰레드의 종료를 기다림
t2.join(); // t2가 참조하는 쓰레드의 종료를 기다림
System.out.println(cnt.getCount());
}
}
class AtomicCounter {
private final AtomicInteger count = new AtomicInteger(0); // 두 쓰레드에 의해 공유되는 변수
public void increment() {
count.incrementAndGet();
}
public void decrement() {
count.decrementAndGet();
}
public int getCount() {
return count.get();
}
}
기존에 int 대신 AtomicInteger를 사용하였다. 이 Atomic 타입은 메소드 시그네처가 ~And~ 하는 형식이다.
현재 내가 접근하려는 데이터의 값이 예상(expect)한것과 동일하다면 데이터를 변경하고 만약 아니라면 아무런 변화를 주지않는 방식이다.
따라서 무작정 데이터를 변경하는 것이 아니라 데이터를 한번 이상이없는지 확인하고 변경하는 것이다.
'스터디 > [white-ship] 자바 스터디(study hale)' 카테고리의 다른 글
| 12주차 과제: 애노테이션 (0) | 2021.02.06 |
|---|---|
| 11주차 과제: Enum (0) | 2021.01.30 |
| 9주차 과제: 예외 처리 (0) | 2021.01.16 |
| 8주자 과제: 인터페이스 (0) | 2021.01.08 |
| 1주차 과제: JVM은 무엇이며 자바 코드는 어떻게 실행하는 것인가. (0) | 2021.01.02 |




댓글